Large language models distill broad knowledge from text corpora.
However, they can be inconsistent when it comes to completing user specified tasks.
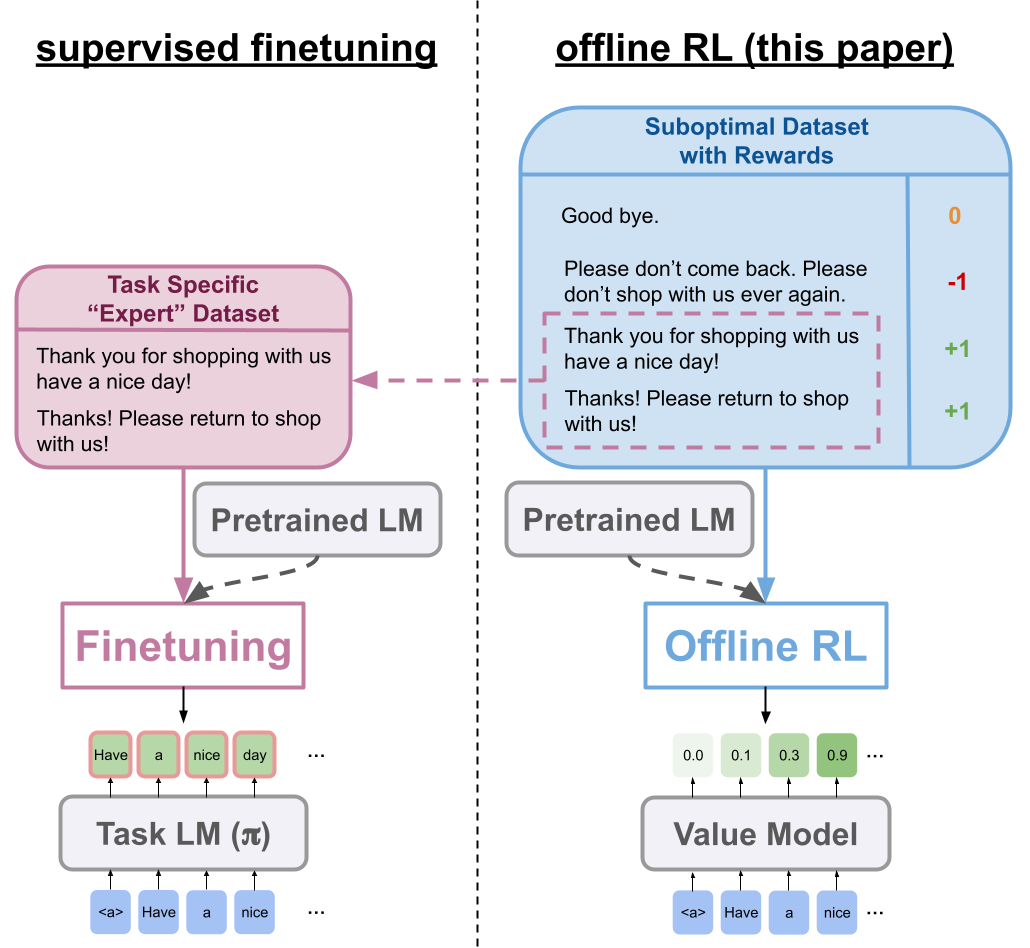
To tackle this challenge, we propose a novel offline RL motivated method, implicit language Q-learning (ILQL), which we demonstrate to be a more effective and easy-to-use task learning method for language models than current approaches based on supervised finetuning or reinforcement learning.
Criteria for Reinforcement Learning on Language Tasks
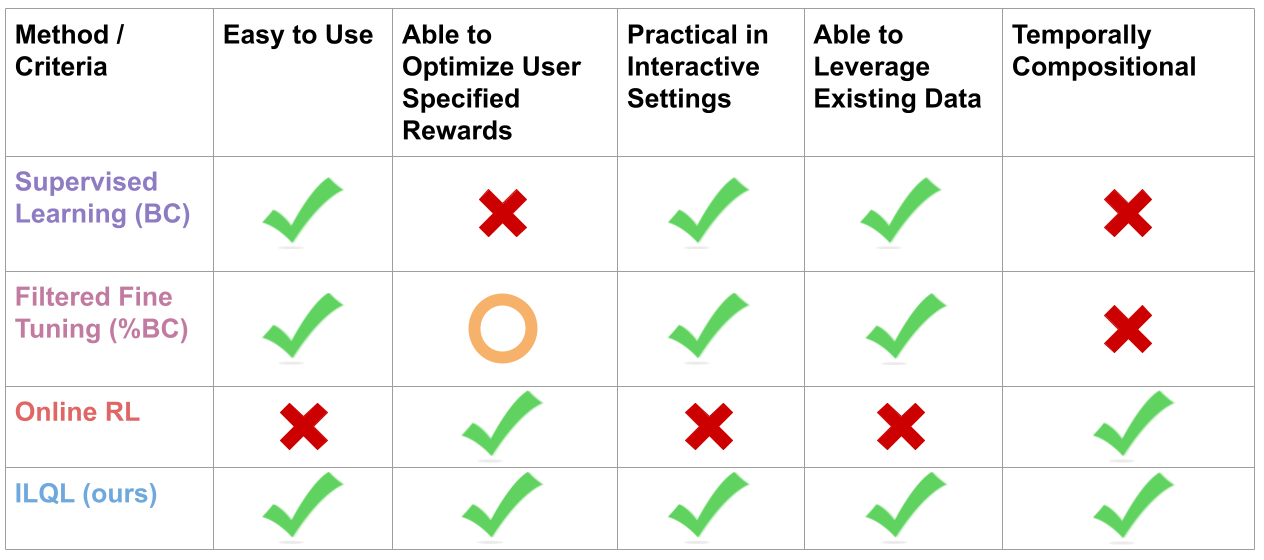
Reinforcement learning (RL) is a promising approach for language task learning. However, contemporary methods involve high systems complexity and expensive human interaction. Instead, an ideal RL method should be: (1) easy to use, (2) able to optimize user specified rewards, (3) practical in interactive settings, (4) able to leverage existing data, and (5) temporally compositional.
Most contemporary approaches to task learning in NLP meet some of the above criteria, but not all. The paradigm of offline RL, on the other hand, has the potential to satisfy all of these criteria by combining supervised learning's ability to leverage existing data (criteria 4) with the powerful reward learning abstraction of RL (criteria 2, 3, 5).
Implicit Language Q Learning
We present Implicit Language Q Learning (ILQL), an effective, easy-to-use offline RL method for language task learning. ILQL combines the strong utility optimization power of dynamic programming based offline RL methods (criteria 5) with supervised learning's ease of use (criteria 1).
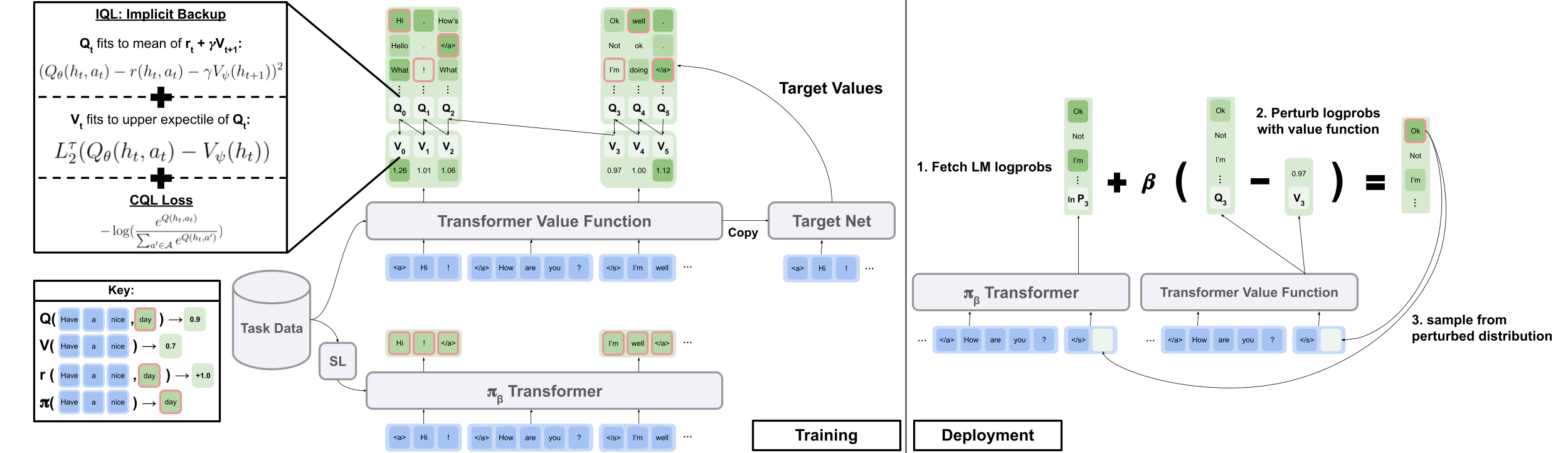
Training ILQL involves fitting a Q function and a value function with support constrained Bellman backups.
At inference time, we use our learned value functions to directly perturb the logits of a standard language model towards reward maximizing behavior.
To ensure that our agents' outputs remain in distribution, we also add a small amount of conservatism loss to our Q function during training. This fixes a calibration issue with our perturbed LM logits.
Wordle as a Preliminary Benchmark Task
The lack of easily configurable task settings and reliable simulated evaluations has arguably slowed progress in applying sophisticated RL algorithms to language and dialogue tasks. To address this, we present Wordle as an easy-to-use but challenging objective benchmark task to test the capabilities of offline RL algorithms.
Our Wordle benchmark task includes the following:
A range of hand designed policies of different skill levels that can be used to synthesize arbitrary offline RL datasets, making it possible to construct highly specific scenarios to unit-test the capabilities of offline RL algorithms on sequence models.
A large dataset of over 200k human Wordle games scraped from Twitter that enables the comparison of offline RL algorithms on a more naturalistic distribution of gameplay.
Natural Language Experiments
We evaluate ILQL on a range of tasks, datasets, and reward functions:
A question asking dialogue task (VD), in which we train agents to optimize reward functions for which the data may be highly suboptimal (e.g. penalizing the asking of yes/no question, which are common in the training data).
An open-ended Reddit comment generation task, in which we train agents to satisfy high variance reward functions based on subjective judgment, such as whether to label a comment as an example of toxic speech or not.
Our dataset of Wordle games scraped from Twitter.
We find that ILQL is generally both better performing and more stable to train than baseline methods in each setting.
Example Dialogues
We present a set of example dialogues produced by our Visual Dialogue agents (in green) optimized for different rewards. Each of our reward functions, from left to right, penalizes the asking of yes/no questions to increasing degrees. As the yes/no penalty increases, our agents learn to ask fewer such questions.
Offline RL for Natural Language Generation with Implicit Language Q Learning