CALM's training teaches the model to better pay attention to the dialogue task context, producing coherent and successful outputs.
Summary
In this work, we view goal-oriented dialogue as a Markov Decision process, interpreting large language models as simultaneously a dynamics model and a policy.
However, the model's training data may contain many sub-optimal task demonstrations. How can we train language models to complete dialogue tasks without inheriting these imperfections in the data?
We approach this question by adopting methods from learning based control, such as task re-labeling and model-based planning to finetune language models in a goal-aware way.
Our resulting method, Context-Aware Language Models (CALM), outperforms SOTA and matches human performance on a practical flight-booking task.
Dialogue Task Relabeling
We turn unsuccessful dialogue demonstrations into successful ones, by swapping out the task context - in this case a flight table - such that the attached dialogue becomes an optimal example of task completion.
In the case of our flight-booking task, there are exponentially many successful tables for a given dialogue, allowing us to significantly increase the number of successful contexts from which our language model can learn.
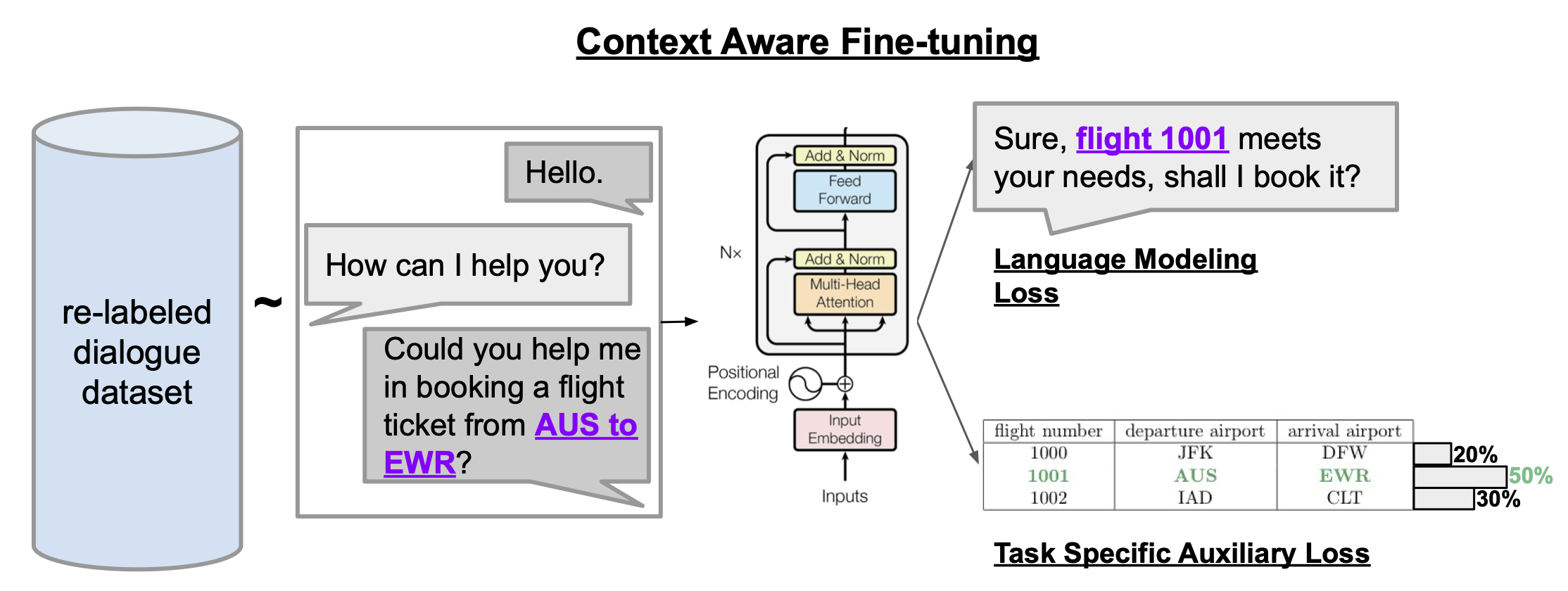
Context Aware Finetuning
The standard language modeling objective alone may be insufficient for successfully learning to utilize the task context.
For example, on our flight-booking task, learning to book the correct flight corresponds to a reletively small entropy decrease under the language model. As a result, the model's learning is primarily spent on modeling the raw form of the dialogue rather than on specifically optimizing for the task.
To rebalance these two objectives, we apply an auxiliary training objective to our model that effectively up-weights the gradients relevant for learning the task.
Model Based Rollout Planning
The standard language modeling objective naturally learns to model both our own utterances (the policy) and the other person's utterances (the dynamics). We use this insight to improve CALM's task success rate by executing a simple model-based planning procedure within the language model.
We sample full rollouts of the dialogue and then re-rank them with a reward model to determine the agent's response.
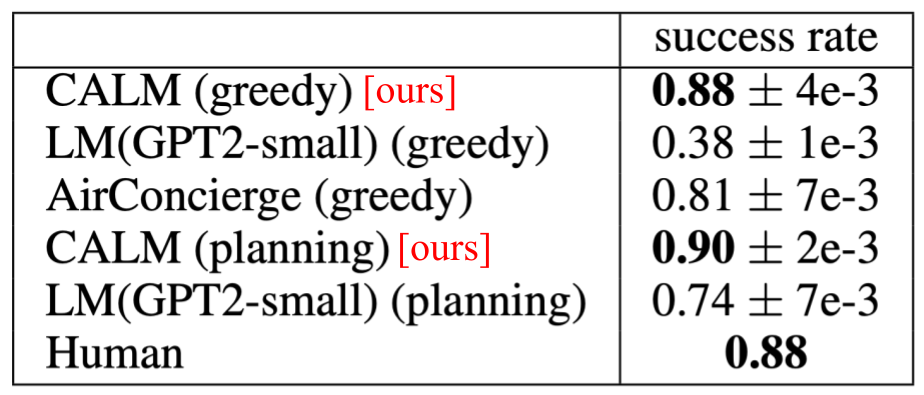
Results
CALM outperforms the previous SOTA (AirConcierge) by approximately 7% on the AirDialogue flight booking task and greatly improves over standard language model training.
When we add model based rollout planning to CALM, it matches human performance on this task.
Compared with AirConcierge, where all reasoning about the task context is done outside of the language model, CALM performs all of the filtering, selecting, and responding with relevant flight table entries within its weights, in a fully end-to-end manner.
A comparison of CALM against baselines. We evaluate models in a simulated evaluation setting.
We present results for both standard greedy decoding (greedy) and model based planning (planning).
Example Dialogues
We present a set of example dialogues produced by CALM (in green) in the simulated evaluation.
Despite being end-to-end, CALM produces highly coherent and sensible outputs.
Context-Aware Language Modeling for Goal-Oriented Dialogue Systems
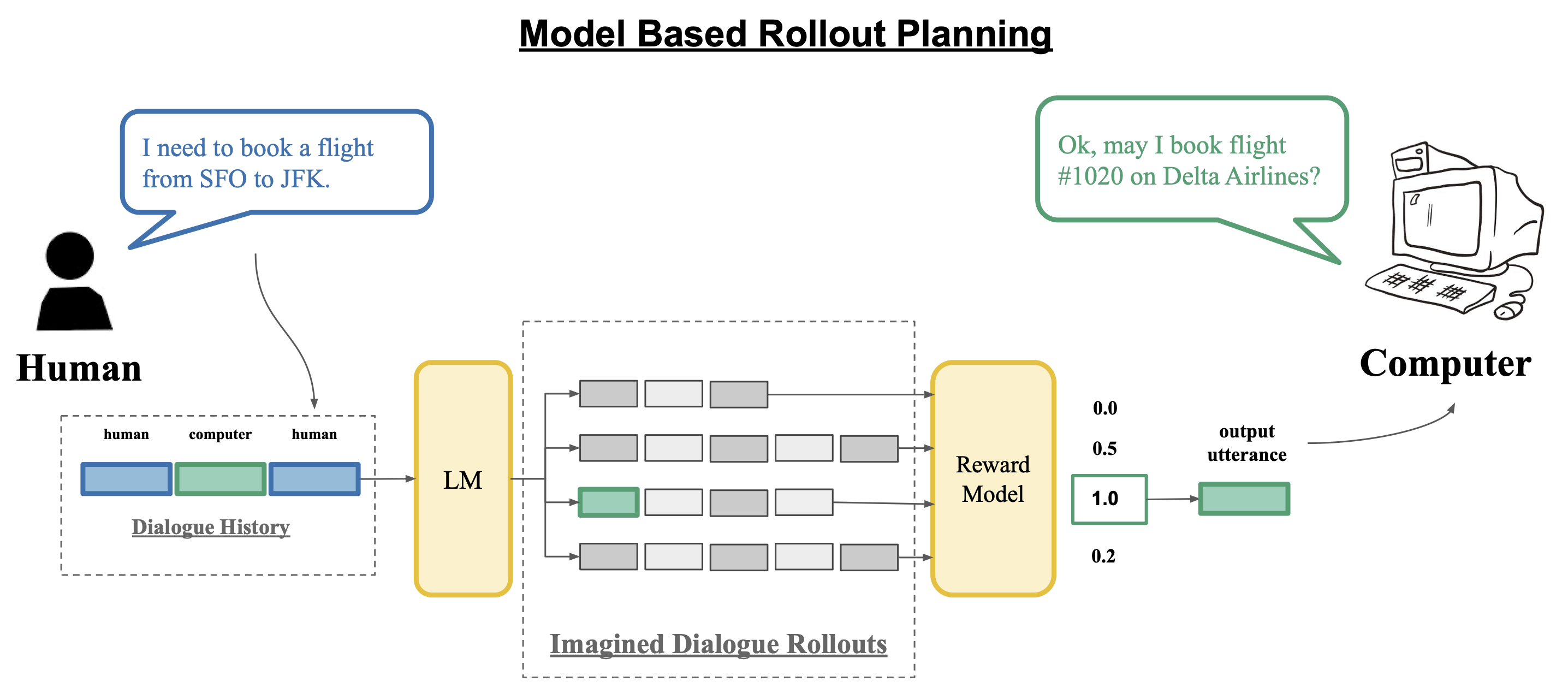 We sample full rollouts of the dialogue and then re-rank them with a reward model to determine the agent's response.
We sample full rollouts of the dialogue and then re-rank them with a reward model to determine the agent's response.